
Choose Your Words Carefully: The Need for Fine-Tuning Large Language Models.
Introduction
A Reddit post titled 'I Gaslit the Chevrolet Support Bot into Thinking It Was Tesla Support' went viral recently. This is just one example of how AI brings opportunities and responsibilities, but also risks, including potential damage to your user experience and brand. The base capabilities of LLMs like GPT-4 are often sufficient for broad applications that aren't specialized. Fine-tuning can teach AI to stay on topic and improve wording, but can your product readily benefit from fine-tuning? Oftentimes, it's not a yes or no answer but a case-by-case consideration that only becomes clearer with experimentation. Let's explore the when, why, and how fine-tuning can improve your AI quality and reliability.
When to Fine-Tune
- Specialized Domain Expertise: Instill domain-specific proficiency into your application. Whether it's navigating legal documents, deciphering medical reports, or wielding technical jargon, fine-tuning equips your LLM with the knowledge and vocabulary to excel in any specialized field.
- Custom Task Requirements and Output Formats: Tailoring LLMs for specific tasks or outputs, such as unique styles, formats, or responses, is essential. This could range from an AI-powered creative writing tool trained in specific literary styles to a software tool requiring the LLM to generate SQL queries.
- Enhanced Privacy, Security, and Fairness: Fine-tuning with a focus on privacy and security is vital when handling sensitive data. For example, a financial services AI might be trained to process personal financial information securely. Additionally, mitigating inherent biases in the base model by training on balanced datasets is crucial, like fine-tuning an HR tool to eliminate gender or racial biases in candidate screening.
- Efficiency and Contextual Understanding: Enhancing a model's understanding of contexts with minimal input prompts leads to more efficient and convenient user interactions. This could be exemplified by a virtual assistant trained to comprehend complex requests with minimal input, or a personal assistant AI that anticipates user needs based on minimal cues.
- Sufficient Data Availability: Most importantly, fine-tune only when you have sufficient data. Ensuring the availability of adequate quality data for practical training is critical. Imagine a news engine recommending clickbait because it was fed garbage data or a chatbot spewing misinformation due to biased training.
When Not to Fine-Tune
- Limited Data Availability: Fine-tuning can be counterproductive without access to ample, high-quality data. It might result in poor performance or overfitting. Typically, while 1000 rows can get you an answer if fine-tuning holds promise, in practice, about 10,000 high-quality and varied examples can get you a robust production model (since they’re in combination with an excellent pre-trained model).
- Rapidly Changing Information: For applications or experiences where information updates frequently, fine-tuning may not offer the desired benefits due to the rapid obsolescence of data. For example, fine-tuning might not be the best solution if your data changes daily - as your costs might be higher. If your data changes more frequently than that, consider using retrieval-augmented generation-type techniques.
- Ethical and Compliance Risks: In cases of concerns about data biases or privacy issues, fine-tuning might amplify these issues instead of resolving them.
Advantages and Disadvantages of Fine-Tuning
Advantages
- Improved Accuracy: Fine-tuning can significantly enhance the model's precision in specific domains.
- Customization: It allows the model to be tailored to specific needs or formats, offering greater utility.
- Efficiency: Fine-tuning leads to an improved understanding of inputs with less need for detailed prompting.
Disadvantages
- Risk of Overfitting: There's a danger of models becoming overly specialized and less versatile.
- Resource Intensive: Fine-tuning requires considerable computational resources and expertise in machine learning.
- Maintenance Needs: Fine-tuned models often require ongoing updates to maintain their effectiveness.
Other Considerations
- Costs: The computational expenses of fine-tuning can be substantial. Consider the maintenance cost as you explore fine-tuning open-source models to reduce API costs.
- Expertise: Complex use cases demand specialized knowledge and skills in machine learning.
- Ethical Concerns: There's a need to ensure that training data is accessible, free from biases, and meets ethical standards.
- Open-Source LLMs: The rise of open-source models offers new opportunities for customization and community-driven enhancements. However, they also necessitate careful data curation and pose challenges regarding model maintenance and support.
- Continuous iteration: Fine-tuning can be effectively done with a few hundred to a few thousand examples for specific tasks. However, you might need tens of thousands of examples for more complex or specialized tasks. It's essential to start with a pilot test, evaluate the performance, and iteratively add more data as needed to improve the model.
Conclusion
The decision to fine-tune LLMs is significant, requiring a careful balance of technical, ethical, and practical considerations. Understanding the appropriate circumstances for fine-tuning and its benefits and drawbacks is crucial for organizations looking to optimize their AI applications.
If you want to try fine-tune yourself, check out AI Hero's open source project.
Baserun now offers Fine-tuning services through our partners. We are running a pilot program that offers a free hands-on fine-tuning service until we observe measurable quality improvements, specifically for complex RAG+Fine-tuning use cases. If you are interested in participating, please drop us at hello@baserun.ai or checkout our documentation.
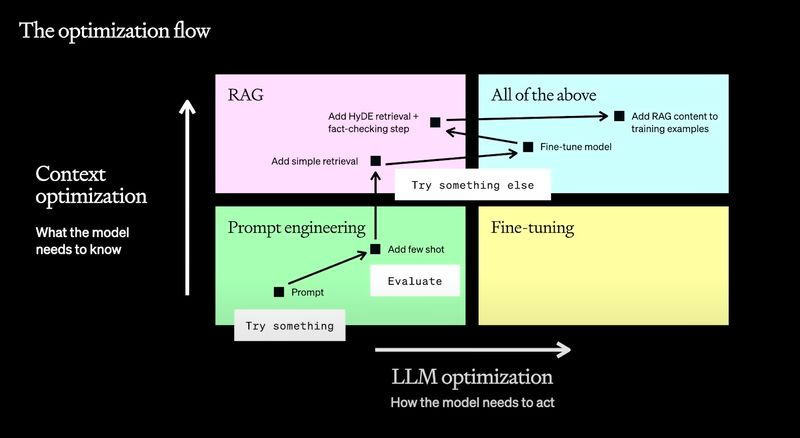
Image from OpenAI developer day talk: A Survey of Techniques for Maximizing LLM Performance
Author: Rahul Parundekar, Founder of AI Hero, Effy Zhang, Founder of Baserun
Member discussion